Building a Production-Oriented Semantic Search System with Milvus and Cross-Encoder Reranking
Introduction
Semantic search is often presented as a modeling problem—choose the right embedding model, tune similarity thresholds, and retrieve results. In practice, however, high-quality semantic search is primarily a system design problem.
This project implements a production-oriented semantic search system that focuses on retrieval quality, performance predictability, and extensibility. Rather than relying on a single model call, the system is explicitly designed as a multi-stage retrieval pipeline, where each stage is responsible for a clearly defined task.
The system emphasizes:
- Clear separation between recall and precision
- Cost-aware retrieval decisions
- Modular components that can evolve independently
While the system can serve as the retrieval backbone of a RAG pipeline, the scope of this project is intentionally limited to semantic retrieval, not answer generation.
High-Level System Architecture
At a high level, the system is composed of four core layers:
- Document Indexing and Vector Storage
- Query Processing and High-Recall Retrieval
- Candidate Filtering
- Precision-Oriented Reranking
Each layer is designed to optimize a different objective and can be tuned or replaced without affecting the rest of the system.
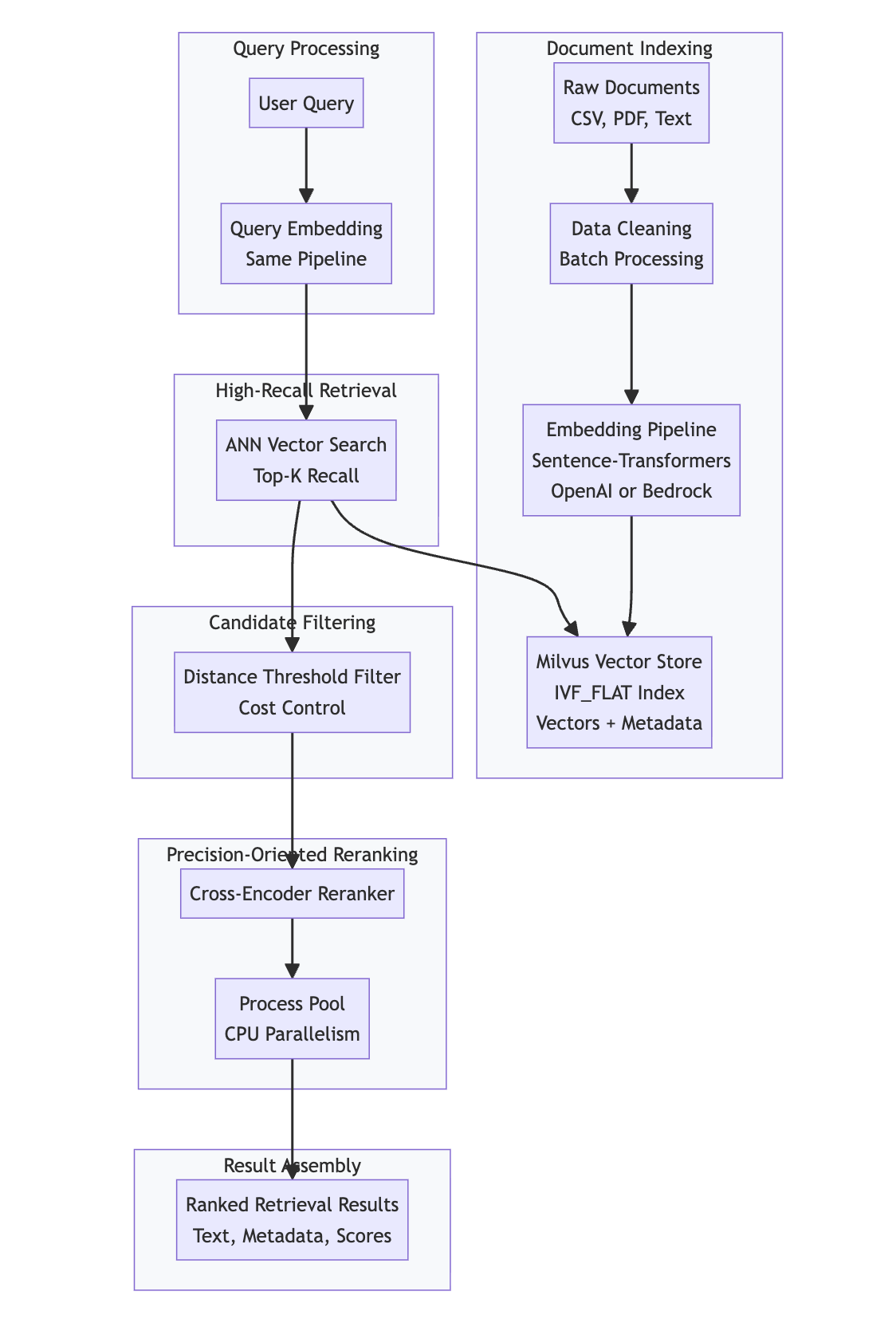
1. Document Indexing and Vector Storage
The indexing pipeline transforms raw textual data into a searchable vector representation.
Text data is ingested in batches, cleaned to remove invalid or empty entries, and converted into dense embeddings using a configurable embedding backend. The system supports multiple embedding providers (local sentence-transformers, OpenAI, AWS Bedrock), allowing flexibility without architectural changes.
Each embedded text chunk is stored in a Milvus collection together with its metadata, such as:
- Original text
- Document or record identifier
- Positional or contextual information
Batch-oriented processing is used to control memory usage and ensure the indexing process can run offline or asynchronously, independent of query traffic.
2. Query Processing and High-Recall Retrieval
When a user submits a query, the system applies the same embedding pipeline used during indexing to ensure consistency in vector space representation.
The resulting query vector is then used to perform approximate nearest neighbor (ANN) search in Milvus. This stage is optimized for high recall rather than perfect ranking:
- Approximate search improves latency and scalability
- The system intentionally accepts imperfect ordering at this stage
- The objective is to retrieve a sufficiently broad candidate set
At this point, results are ordered only by vector similarity, which provides a coarse semantic signal.
Design Rationale:
The system explicitly separates recall from precision. Vector embeddings excel at identifying semantically related content but are insufficient for fine-grained ranking. By accepting imperfect ordering at this stage, we can optimize for speed and coverage, leaving precision to the reranking stage.
3. Candidate Filtering
Between retrieval and reranking, the system introduces an explicit candidate filtering layer based on vector distance.
Only candidates whose distance falls below a configurable threshold are forwarded to the reranking stage. This step is not intended to refine ranking quality but to serve as a system-level cost control mechanism.
Filtering reduces:
- The number of expensive Cross-Encoder evaluations
- Overall CPU usage
- Tail latency under load
Crucially, filtering and reranking are treated as separate responsibilities:
- Filtering determines whether a candidate is worth further evaluation
- Reranking determines how relevant qualified candidates are relative to each other
Cost Control Strategy:
The distance threshold is not a relevance heuristic—it is a resource management tool. Cross-Encoder inference is expensive. Filtering out distant candidates early prevents wasted computation on results that are unlikely to be relevant, stabilizing latency and reducing CPU pressure under load.
4. Precision-Oriented Reranking
The reranking stage applies a Cross-Encoder model to evaluate relevance at a finer granularity.
Unlike bi-encoder embeddings, the Cross-Encoder jointly processes the query and candidate text, enabling deeper semantic interaction and more accurate relevance scoring. Candidates are assigned a reranking score and reordered accordingly.
Because Cross-Encoder inference is CPU-intensive, reranking is optimized using:
- Process-based parallelism (to bypass Python’s GIL)
- A shared process pool reused across requests
- Sequential execution for small candidate sets to avoid parallelization overhead
This stage is responsible for the final ranking of search results.
Performance Optimization:
| Strategy | Implementation | Benefit |
|---|---|---|
| Process Pool | Multi-process parallelism | Bypass Python GIL, true multi-core utilization |
| Shared Pool | Reused across requests | Reduce process creation overhead |
| Adaptive Execution | Sequential for small sets | Avoid parallelization overhead |
5. Output and System Scope
The system returns ranked retrieval results, not synthesized answers.
Each result includes:
- Original text
- Associated metadata
- Vector distance
- Reranking score
By keeping the output grounded in retrieved evidence, the system remains transparent, debuggable, and suitable as a foundation for future RAG-style generation without coupling retrieval quality to LLM behavior.
Design Rationale and Key Engineering Decisions
The architecture above reflects several deliberate design decisions. The following sections explain the reasoning behind the most important ones.
1. Semantic Search Is Treated as a System, Not a Model
This project treats semantic search as a pipeline of responsibilities, not a single model invocation.
Separating recall and precision allows each stage to be optimized independently:
- Vector retrieval focuses on speed and coverage
- Reranking focuses on semantic accuracy
This separation simplifies tuning, improves robustness, and avoids overloading any single model with conflicting objectives.
2. Embeddings Are Used for Recall, Not Final Ranking
Dense embeddings are effective for identifying semantically related content but insufficient for fine-grained ranking.
Rather than forcing embeddings to produce perfect ordering, the system explicitly delegates ranking precision to the Cross-Encoder. This reduces complexity in the embedding stage and makes model upgrades less risky.
3. Distance-Based Filtering Is a Cost Control Strategy
The distance threshold is not a relevance heuristic—it is a resource management tool.
Cross-Encoder inference is expensive. Filtering out distant candidates early prevents wasted computation on results that are unlikely to be relevant, stabilizing latency and reducing CPU pressure under load.
4. Filtering and Reranking Are Explicitly Separated
By separating filtering from reranking, the system maintains clear conceptual boundaries:
- Filtering answers “Is this candidate worth scoring?”
- Reranking answers “How relevant is this candidate?”
This clarity makes future extensions—such as adaptive thresholds or query-aware recall policies—straightforward to implement.
5. Process-Based Parallelism Is Used for Reranking
Reranking is CPU-bound and subject to Python’s Global Interpreter Lock.
Multi-process parallelism enables true multi-core utilization, while controlled worker counts and fallback logic ensure predictable performance across different workloads.
6. Indexing and Querying Share the Same Embedding Pipeline
Both document indexing and query processing use the same embedding model and preprocessing logic.
This guarantees consistency in vector space representation and prevents subtle retrieval failures caused by embedding drift or misconfiguration.
7. The System Is Retrieval-Focused by Design
The system intentionally stops at ranked retrieval results rather than generating answers.
This choice preserves transparency, simplifies debugging, and keeps the architecture flexible. Answer generation can be layered on later without entangling retrieval correctness with generative behavior.
Technology Stack
| Layer | Technology | Purpose |
|---|---|---|
| Vector Database | Milvus | High-performance vector storage with IVF_FLAT index |
| Embedding Models | Sentence-Transformers, OpenAI, AWS Bedrock | Flexible embedding backend support |
| Reranking | Cross-Encoder models | Fine-grained relevance scoring |
| Parallelism | Process Pool | CPU-bound task parallelization |
| Data Processing | Batch Processing | Efficient document ingestion |
System Flow
The complete system flow can be visualized as follows:
-
Document Indexing Pipeline:
- Raw Documents (CSV, PDF, Text) → Data Cleaning → Embedding Pipeline → Milvus Vector Store
-
Query Processing Pipeline:
- User Query → Query Embedding (Same Pipeline) → ANN Vector Search → Candidate Filtering → Cross-Encoder Reranker → Result Assembly
-
Result Output:
- Ranked Retrieval Results (Text, Metadata, Scores)
Future Extensions
This system is designed to be modular and extensible. Possible future improvements include:
- Adaptive Thresholds: Query-aware distance thresholds based on query characteristics
- Hybrid Retrieval: Combine dense vector search with sparse keyword-based retrieval
- Query Expansion: Enhance query representation with synonym expansion or query rewriting
- Metadata Filtering: Pre-filter candidates based on metadata constraints before vector search
- Multi-Stage Reranking: Apply multiple reranking models in sequence for different precision levels
- Caching Layer: Cache frequently accessed query results to reduce computational load
Conclusion
This project implements a semantic search system that treats retrieval as a multi-stage pipeline rather than a single model invocation. The architecture separates recall and precision into distinct stages, with each stage optimized for a specific objective.
The system design emphasizes:
- Separation of recall and precision through dedicated stages for vector search and reranking
- Cost-aware filtering to control computational resources before expensive reranking
- Modular architecture where components can be tuned or replaced independently
- Shared embedding pipeline for consistency between indexing and querying
- Retrieval-focused output that returns ranked results without answer generation
This approach allows the system to serve as a standalone semantic search solution or as a retrieval layer for RAG applications, with clear boundaries between retrieval and generation stages.
- Semantic Search
- Milvus
- Vector Search
- RAG
- Cross-Encoder
- ANN
- Embeddings
- Information Retrieval
- System Design